Executando Modelos do Deepseek Localmente com Ollama no Windows e MacOS

Introdução
Recentemente, testei o Ollama tanto no Mac quanto no Windows. Para quem não conhece, o Ollama é uma ferramenta que permite rodar modelos de linguagem (LLMs) localmente, sem depender de serviços externos em nuvem. Você pode escolher diferentes modelos e realizar consultas (prompts) diretamente no seu computador, seja usando CPU ou, quando disponível, GPU.
Neste post, vou compartilhar a minha experiência de instalação do Ollama nas duas plataformas, como habilitei a execução via GPU no Windows usando CUDA e cuDNN, bem como um exemplo de aplicação em Java (Spring Boot + Spring AI) para se comunicar com o modelo Deepseek rodando localmente via Ollama. Ao final, apresentarei também alguns testes de desempenho que fiz, questionando os modelos (de tamanhos diferentes) sobre quem foi Martin Luther King, com seus respectivos tempos de resposta.
Instalação no macOS
Passo a passo
1) Instalação:
Via Homebrew (caso não tenha, instale o Homebrew aqui):
$ brew install ollama
Se preferir instalar diretamente sem usar o Homebrew, você pode baixar o binário do Ollama pelo site oficial. Acesse o link abaixo para fazer o download diretamente para macOS:
2) Verifique se o Ollama foi instalado:
$ ollama help
Se o Ollama responder com a lista de comandos, a instalação foi concluída.
Teste de execução
-
Para listar os modelos disponíveis:
$ ollama list
-
Para rodar um modelo (por exemplo, um “hello” básico), use:
$ ollama run deepseek-r1:1.5b
-
Para remover um modelo:
$ ollama rm nome-do-modelo
Experiência pessoal no Mac
Eu tenho um MacBook Air M3 e tentei rodar o modelo Deepseek-r1:14b, mas não ficou muito suave. Ele exigiu bastante processamento. Sendo assim, optei por rodar a versão de 8b do modelo para uma experiência mais fluida.
Instalação no Windows
Habilitando GPU com CUDA e cuDNN
Se você possui uma placa de vídeo NVIDIA e quer acelerar a execução dos modelos, será necessário instalar:
Depois de instalados, verifique se seu sistema reconhece o CUDA corretamente:
$ nvcc --version
No meu caso, ao executar o comando acima, obtive a seguinte saída:
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2025 NVIDIA Corporation Built on Wed_Jan_15_19:38:46_Pacific_Standard_Time_2025 Cuda compilation tools, release 12.8, V12.8.61 Build cuda_12.8.r12.8/compiler.35404655_0
Outro comando útil:
$ nvidia-smi
Este comando mostra informações detalhadas da sua GPU, utilização de memória, temperatura e consumo de energia. A imagem abaixo (captura da minha máquina) mostra meu nvidia-smi com a placa RTX 4080, rodando em um desktop com processador Intel Core i9-9900KF e 32GB de memória RAM:
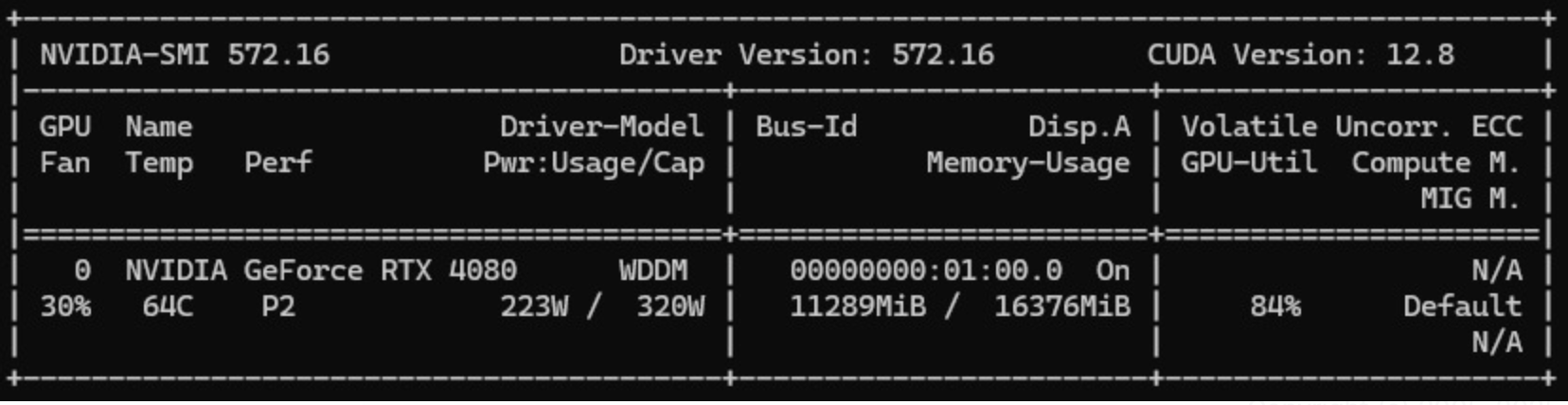
No meu caso, enquanto rodava o modelo Deepseek-r1:14b, a GPU estava sendo utilizada em cerca de 84%. Já para a versão 32b, notei que a carga se distribuiu bastante entre CPU e GPU.
Executando o Ollama no Windows
Assumindo que você já tenha colocado o binário do Ollama em uma pasta do PATH ou que esteja chamando-o diretamente:
$ ollama help
-
Liste os modelos instalados:
$ ollama list
-
Rode o modelo:
$ ollama run deepseek-r1:14b
-
Remova um modelo:
$ ollama rm deepseek-r1:14b
-
Baixe (pull) um modelo, caso não exista localmente:
$ ollama pull deepseek-r1:8b
Exemplo de Aplicação Java
Para demonstrar como podemos integrar a execução local do Ollama com uma aplicação, criei um exemplo utilizando Spring Boot e Spring AI. O objetivo é enviar prompts para o modelo local e retornar a resposta pela API REST.
O repositório com o projeto completo está em: demo-ollama-deepseek
Pom.xml
A seguir, um trecho do arquivo pom.xml que mostra como estou definindo as dependências:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.2</version>
<relativePath/>
</parent>
<groupId>com.gasparbarancelli</groupId>
<artifactId>ollama-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ollama-demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>23</java.version>
<spring-ai.version>1.0.0-M5</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</project>application.properties (ou .yml):
spring.application.name=ollama-demo spring.ai.ollama.chat.model=deepseek-r1:14b
Classe Principal
Abaixo, o exemplo de classe principal. Observe que estamos retornando um objeto RespostaChat que inclui tanto o texto retornado pelo modelo quanto o tempo gasto em sua execução:
package com.gasparbarancelli.ollama_demo;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
@RestController
@RequestMapping("/")
public class OllamaDemoApplication {
private final OllamaChatModel chatModel;
public OllamaDemoApplication(OllamaChatModel chatModel) {
this.chatModel = chatModel;
}
public static void main(String[] args) {
SpringApplication.run(OllamaDemoApplication.class, args);
}
@GetMapping
public RespostaChat chatbot(@RequestParam("message") String message) {
long inicio = System.currentTimeMillis();
var mensagemDoUsuario = new UserMessage(message);
var prompt = new Prompt(mensagemDoUsuario);
var respostaDoChat = chatModel.call(prompt);
var saida = respostaDoChat.getResult().getOutput().getText();
long fim = System.currentTimeMillis();
long tempoGastoMs = fim - inicio;
long minutos = tempoGastoMs / 60000;
long resto = tempoGastoMs % 60000;
long segundos = resto / 1000;
long milissegundos = resto % 1000;
String tempoGastoFormatado = String.format(
"%d minuto(s), %d segundo(s) e %d milissegundo(s)",
minutos, segundos, milissegundos
);
return new RespostaChat(saida, tempoGastoFormatado);
}
public record RespostaChat(String texto, String tempoGasto) {}
}Observação: Erro ao tentar rodar um modelo não “instalado”
Se você configurar o application.properties para um modelo que ainda não foi “instalado” pelo Ollama (por exemplo, deepseek-r1:8b), ao iniciar a aplicação ou tentar acessar o endpoint você poderá se deparar com o erro:
java.lang.RuntimeException: [404] Not Found - {"error":"model \"deepseek-r1:8b\" not found, try pulling it first"}
Para corrigir, basta executar o comando abaixo no terminal e então reiniciar ou chamar novamente a aplicação:
$ ollama pull deepseek-r1:8b
Assim, o modelo será baixado (caso ainda não esteja no seu cache local) e passará a funcionar normalmente.
Testes de Desempenho (Modelos Deepseek)
A seguir, compartilho os resultados de uma consulta que fiz aos modelos Deepseek de diferentes tamanhos (32b, 14b, 8b, 7b e 1.5b). A pergunta foi:
GET http://localhost:8080/?message=who%20was%20martin%20luther%20king
Para cada modelo, obtive uma resposta em JSON contendo o texto da resposta e o tempo de execução:
Deepseek 32b
{
"texto": "<think>\n\n</think>\n\nMartin Luther King Jr. ...",
"tempoGasto": "3 minuto(s), 9 segundo(s) e 0 milissegundo(s)"
}
Deepseek 14b
{
"texto": "<think>\n\n</think>\n\nMartin Luther King Jr. (1929–1968) was a prominent African American civil rights leader...",
"tempoGasto": "0 minuto(s), 7 segundo(s) e 668 milissegundo(s)"
}
Deepseek 8b
{
"texto": "<think>\n\n</think>\n\nMartin Luther King Jr. was a prominent American civil rights activist...",
"tempoGasto": "0 minuto(s), 4 segundo(s) e 578 milissegundo(s)"
}
Deepseek 7b
{
"texto": "<think>\n\n</think>\n\nMartin Luther King Jr. (1929–1968) was an American civil rights leader...",
"tempoGasto": "0 minuto(s), 3 segundo(s) e 752 milissegundo(s)"
}
Deepseek 1.5b
{
"texto": "<think>\n\n</think>\n\nMartin Luther King, Jr. (1921–), was the prominent leader of the Black Radical Movement...",
"tempoGasto": "0 minuto(s), 1 segundo(s) e 390 milissegundo(s)"
}
Podemos observar que, conforme o tamanho do modelo aumenta, o tempo de resposta costuma ser maior (no teste, o 32b levou cerca de 3 minutos para responder). Já os modelos menores (14b, 8b, 7b e 1.5b) responderam em poucos segundos. No entanto, é importante destacar que, quanto maior o modelo, melhor costuma ser a qualidade das respostas, com maior precisão, coerência e riqueza de detalhes, justificando o tempo adicional de processamento.
Conclusão
Mac: A instalação via Homebrew é bastante simples. Para Macs com menor poder de processamento (como o MacBook Air M3, no meu caso), modelos muito grandes (como 14b ou 32b) podem não rodar tão suavemente. A solução é optar por modelos menores (8b ou similares).
Windows: O Ollama funciona bem, especialmente quando sua GPU é compatível. No meu teste com RTX 4080, a utilização foi por volta de 85% no modelo 14b, garantindo respostas rápidas. Além disso, esse desktop conta com um Intel Core i9-9900KF e 32GB de memória RAM, ajudando no desempenho geral. Para modelos maiores (32b), notei uso intensivo tanto de CPU quanto de GPU.
Exemplo Java: Se você quer integrar um modelo local com sua aplicação web, Spring Boot + Spring AI faz todo o trabalho pesado.
Para mais detalhes e o código completo, acesse o meu repositório: demo-ollama-deepseek
Caso queira explorar outros modelos, dê uma olhada em:
E não se esqueça dos comandos básicos do Ollama:
-
ollama list– Lista os modelos disponíveis. -
ollama run <NOME-DO-MODELO>– Executa um modelo específico. -
ollama rm <NOME-DO-MODELO>– Remove um modelo instalado. -
ollama pull <NOME-DO-MODELO>– Baixa o modelo caso não exista localmente. -
ollama help– Exibe a ajuda com todos os comandos disponíveis.
Espero que este guia ajude você a instalar o Ollama, configurar GPU no Windows e criar suas próprias integrações com modelos locais!